

一文读懂 Fabarta ArcGraph 图数据库丨技术解读
导读 本文将深入探讨图数据库的发展历程、Fabarta 自研图数据库 ArcGraph 的产品优势,以及 ArcGraph 如何充分利用图和向量数据库的融合优势,为 AI 技术的发展提供强大支持。
图数据库最早诞生于上世纪六七十年代,起源于对复杂网络结构的理解和处理需求。随着社交网络、知识图谱、推荐系统等领域的发展,传统的关系型数据库在处理大规模、复杂的网络结构数据时面临挑战,这促使了图数据库技术从小规模图存储的 1.0 时代快速演进到分布式 2.0 时代。图数据库以其独特的数据模型和查询优势,逐渐在各种复杂分析场景中展现出强大的实力。近几年,人工智能技术快速发展,对新时代 AI 数据基础设施也提出了更高的要求,图数据库以其强大的关联分析能力满足了 AI 对复杂关系处理的需求。图和向量的融合技术也实现了多模态的数据处理,为 AI 的发展提供了新的可能性。接下来,我们将深入探讨图数据库的发展历程、Fabarta自研图数据库 ArcGraph 的产品优势,以及 ArcGraph 如何充分利用图和向量数据库的融合优势,为 AI 技术的发展提供强大支持。
01 图数据库架构演进
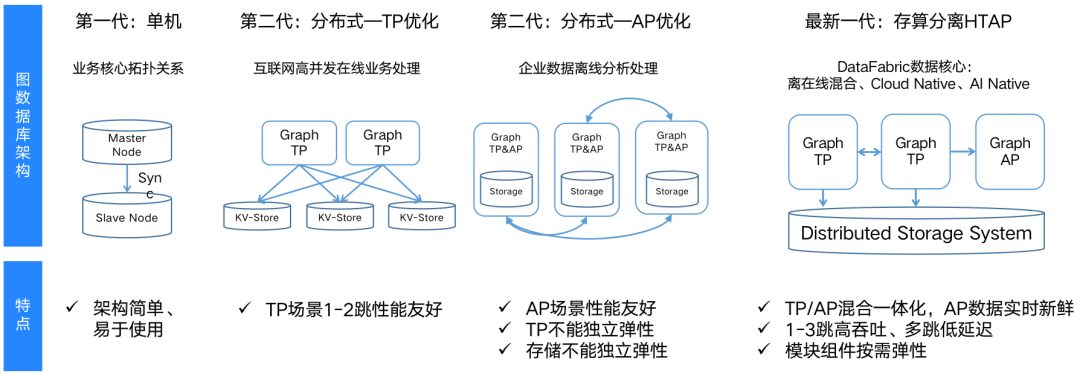
常用图数据库架构对比上图所示为当前几种主流的图数据库技术架构。实际上,图数据库架构发展趋势与关系数据库的发展趋势相似,每种架构都有其诞生的背景及优缺点。
单机架构
单机架构采用单机计算和存储,其中以 Neo4J 为代表,架构简单并且方便企业快速部署应用。但该架构无法快速横向扩展算力和存储资源,比较适合小数据量、科研项目或者单一场景的图应用。
单机查询&分布式存储架构
此类架构目前是开源界的主要架构,以 JanusGraph、HugeGraph 为代表,实现了数据的分布式存储。但是此架构进行查询和简单计算时需单一的查询节点来实现,在大数据量、多跳和重计算分析等场景下面临较大的挑战。目前,开源图数据库的主要用户是互联网客户。过去,互联网客户在图的主要使用场景为搜索、广告、推荐,意味着更多需要一跳和二跳的支持,三跳以外的关系信息对于推荐的价值已经不大。该架构在过去互联网搜索、广告、推荐场景下发挥了重要作用,但目前互联网目前也有越来越多的场景需要多跳信息的支持,比如互联网风控等。这种架构由于查询和计算都是一个单机节点,本质上无法融合图计算能力(因为图计算框架都是分布式计算方案,后文会有介绍),无法实现实时的动态图查询并实时计算的能力,该类架构在侧重多跳关系和分析的场景面临较大的性能挑战,比如反洗钱、反欺诈等场景。
分布式查询和存储&MPP 架构
此类架构是真正的分布式架构,解决可了上述架构的大部分缺陷,性能有明显提高,可以实现图数据库和图计算一体化。但此类架构主要是 MPP 的架构实现方式,计算和存储耦合,无法根据业务和使用量等来动态决定计算和存储节点数目与调度机制。可以说不是真正意义上的云原生和存算分离,但鉴于该架构有一定的先进性,目前开源界还没有该类架构的图数据库,只存在于闭源商业产品中。
云原生分布式&存算分离架构
此类架构不仅仅做到了分布式查询和分布式存储,同时还是云原生和存算分离。它天然适合云上部署,并且计算和存储分离,可以有效利用云上计算和存储的弹性特点,同时存储不再要求绑定单一的存储系统,可以有效支持云上存储,比如 OSS、S3 等。此类架构以 ArcGraph 为代表,特别适合大数据量、多跳和查询计算一体化的需求,可以有效解决一个客户多种业务场景的发展要求,并非常适用基于云来构建一体化的基础设施来提供统一的图数据库和计算服务。
02 ArcGraph 产品架构
作为一家 AI 基础设施公司,Fabarta 在引擎层打造了面向 AI 的 ArcNeural 多模态智能引擎,实现了图、向量与 AI 推理能力的深度融合,将传统数据库的“存储&计算”架构演进为 AI-Native 的“记忆&推理”架构,可以为 AI 应用提供私有记忆和精确可解释的推理。ArcGraph 是 ArcNeural 中的图引擎,是公司自主设计和研发的一款分布式、云原生的高性能图 HTAP 数据库,是一款同时支持图查询和图分析的存查分析一体化的融合性图数据库引擎。ArcGraph 全面兼容 OpenCypher 语言,与同类产品相比多跳性能也有显著的性能提升。结合不同的应用场景,可以灵活切换单机、主备高可用或分布式多种部署方式。通过融合向量引擎和低代码化 AI 计算平台,提供大模型时代数据、算力和模型的一体化,构建大模型时代的 AI 基础设施,帮助企业快速构建大模型时代的 AI 应用。
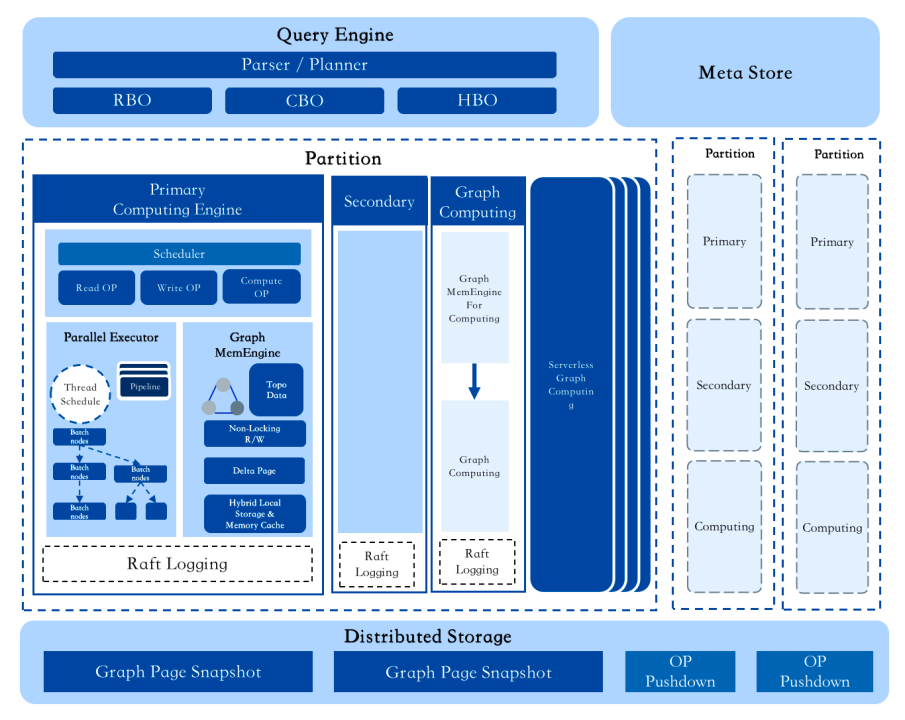
查询引擎( Query Engine)
查询引擎是 ArcGraph 的大脑,它是无状态的 Cypher Query Compiler 引擎。该查询引擎通过采用 Rust 的 Logos 库和 Nom 库来解析 Cypher 语言并生成 AST。随后,通过 Planner 进行转换,利用自研的具备自上向下和自下向上优化框架(借鉴 Cascade 框架的思想),同时结合点和边统计信息以及历史 Plan 信息,通过 RBO、CBO 和 HBO 的多轮 Plan 优化,生成高效的执行计划。
计算引擎(Computing Engine)
高性能的计算引擎是 ArcGraph 的发动机,采用了 MPP 的架构;该计算引擎承担多项重要任务,包括执行计划的 DAG 切割、 DAG 在分布式 computing 节点间的分发,以及执行计划的启动、暂停、恢复和删除等生命周期管理。最后,计算引擎会暂时缓存计算结果,通过 gRPC 按批发送给客户端。
由于系统采用存、算分离的分布式架构, ArcGraph 的计算引擎采用中心化的 TSO 分配策略以及分布式的 MVCC 能力,以确保分布式事务的隔离性和一致性。同时,它还采用了 multi-raft 协议以确保 WAL log 在多个计算节点的一致性,从而天然具备了分布式节点之间的 HA 功能。
图数据(点和边)通过灵活的分区策略存储在不同 Partition 中,这些 Partition 可由分布式计算节点池中的不同计算节点提供服务。通过调整分区策略,可以达到优化分布式执行的效果,例如将相关性的点和边数据由同一个计算节点提供服务,从而降低图查询经典多跳时的分布式通讯成本。
存储引擎(Storage Engine)
存储引擎采用 share-nothing 的架构,提供 ArcGraph 的持久层服务。存储层采用多级存储系统,首先是提供高性能数据访问的内存引擎,提供图拓扑信息、MVCC、脏页管理;然后是本地 SSD 固态存储,提供持久化 WAL 日志服务,并借助 Raft 协议来保证节点间的分布式一致性;最后是提供异步写入的远端存储,根据业务系统需要,可以灵活对接单机 RocksDB,分布式 TiKV 或云对象存储(OSS)。
03 ArcGraph 产品优势
云原生
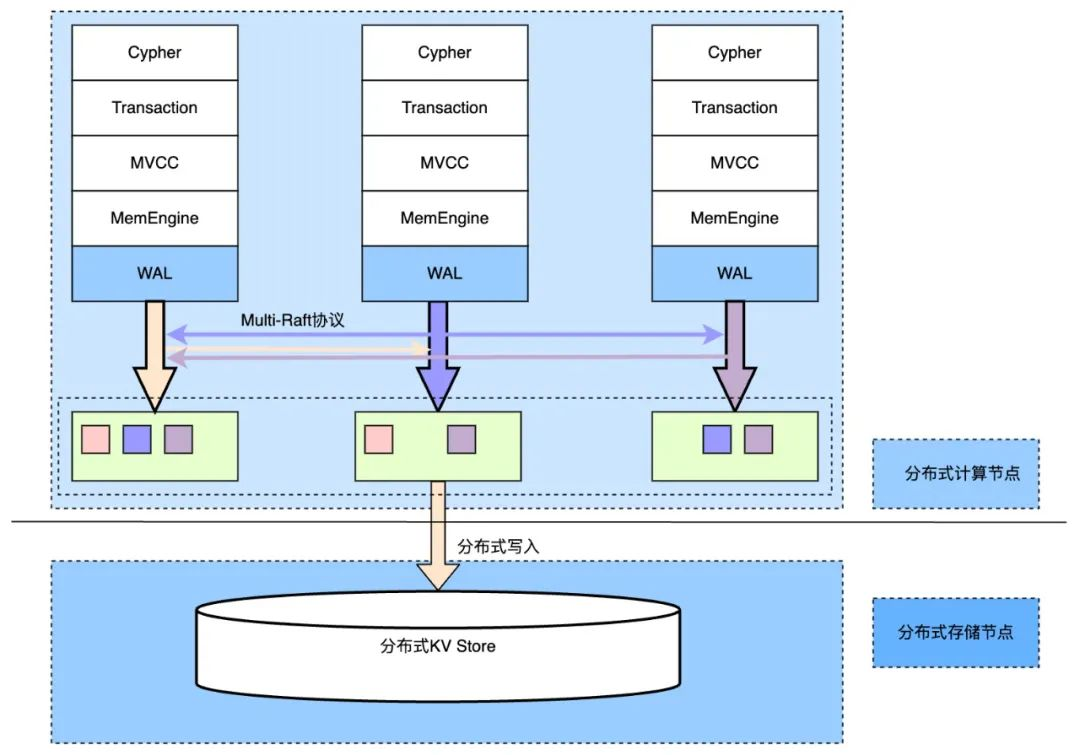
ArchGraph 沿袭了当前云原生关系数据库流行的“日志即数据” 思想,设计了存储和计算分离的图数据库架构。存储和计算由两个松耦合、独立无缝扩展的服务来处理,从而提高了系统可用性以及并发查询的性能。此外,Fabarta 还创新性地设计了计算层缓存 WAL 日志的方案,提出了 Semi-Stateful 概念。系统的 WAL 日志通过采用实现分布式一致性算法的 multi-raft 协议,来达到高可用和计算节点间的一致性。高性能的计算节点包含无状态的 QueryEngine(QE)和半状态的 ComputingEngine(CE),这种设计可以无缝扩展以支持大图查询。基于查询热度以及灵活的分区策略,可以将大图按照切边的方式分成多个小图,每个小图的存、查和分析任务可由专门的计算节点来服务。对于分布性扩展,可采用针对 ID 或点/边类型的一致性 Hash 分区策略,有效地实现负载均衡和热点抑制,确保扩展过程中数据的一致性,并对业务零感知。此外,可通过单独增加节点来进行图分析任务,实现图查询和图分析的资源隔离。对于日常计算任务负载的变化,可以通过灵活地扩展或缩减计算节点来实现计算任务的动态调整。存储节点只作为传统数据库的持久层,通过 Replay WAL 日志进行周期性 Checkpoint,存储节点可以随着系统数据量的大小进行动态扩缩容。同时根据业务需要可以对接单机 RocksDB,分布式 TiKV 或云厂商提供的对象存储系统(如 OSS)。
原图内存引擎
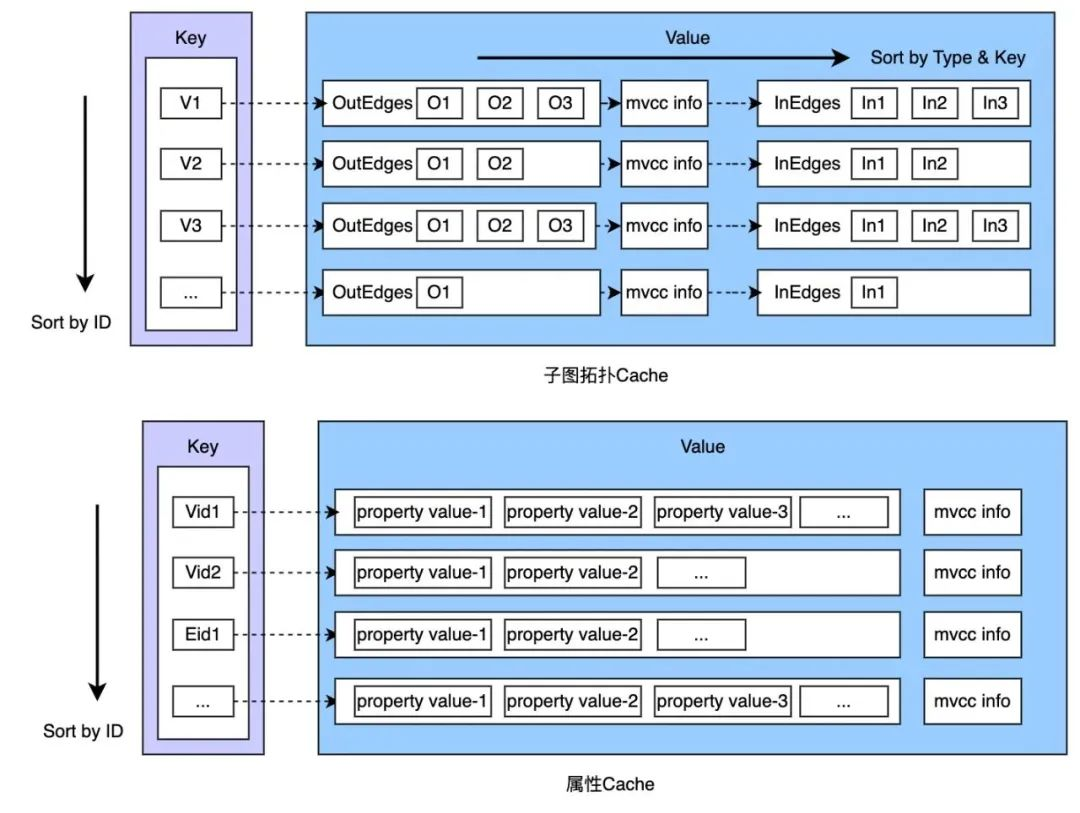
存储和计算分离的带来了一个优势,即计算节点无需配置很大的存储介质来存储图的点和边数据。这些数据可能非常大,而且大部分是冷数据(访问频率较低)。为了避免在每次查询数据时计算引擎都必须下探到存储节点,同时提高查询性能、降低计算节点和存储节点间的往来流量,ArcGraph 为每个计算节点提供数据缓存(Cache)层。其中包含:
(1)子图的拓扑结构,ArcGraph 采用邻接表数据结构来存储;之所以不用邻接矩阵是因为图数据中除了大 V 节点外,大部分节点的边数远小于点的数量,从而避免稀疏矩阵造成的内存浪费;
(2)基于 LRU 的访问热点的点/边属性 Cache。
(3)index buffer 和 mvcc 多版本数据。
当前内存引擎在快速迭代研发和优化中,会借鉴业界领先的一些理念和设计,如跳表等高效数据结构,进一步提升内存引擎性能。同时,也将借鉴矩阵计算、CSR 等技术加速内存多跳性能。
分布式查询
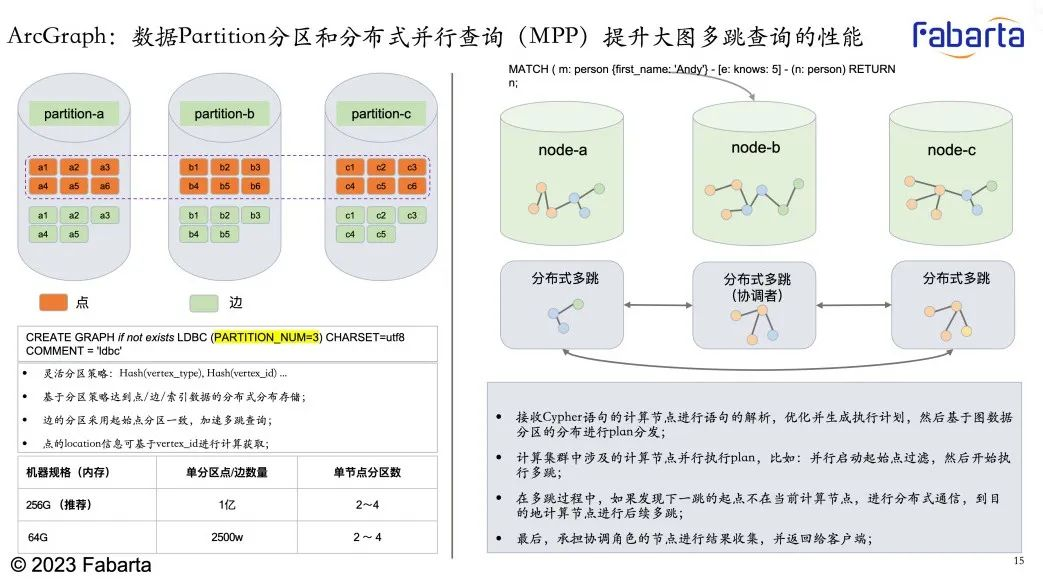
ArcGraph 是一个实现分布式查询的图数据库,计算层采用 MPP 分布式架构,每个计算节点采用基于 Push 模式的向量化执行引擎,实现原理大致如下:
(1)执行计划切割:基于 QueryEngine 优化后的物理执行计划,执行引擎先结合算子的属性(例如是否是 pipeline breaker,如 Hash Join 算子),完成对执行计划进行切割,最终生成 DAG 图,基于 DAG 间的依赖关系,对其中的每个子 DAG 进行分布式并行调度执行;
(2)计划分发:根据执行计划中涉及数据 partition 分布信息,把执行计划分发到所涉及的 partition leader 节点;
(3)分布式调度执行:由 Co-ordinator 节点发起 pipeline ,并在计算节点 culster 上分布式行执行;每个计算节点上的计算引擎采用 push 模型,并结合 Batch 方式进行向量化执行,同时算子内部利用协程进行计算加速(例如并行执行多节点的 Expand),高效完成执行计划的分布式并行执行计算;
在计算过程中,如果有些算子产生大量中间结果(如 aggregate 算子),计算引擎具备“Flush to Disk”的功能,可以物化部分结果到外存,从而避免 OOM 的问题。在有些场景中,如果计算引擎生成结果的速度快于 Client 拉取数据的速度,引擎会自动暂停 Pipeline 的执行,等待 Client 消费一定量 ResultCache 中数据后再恢复执行。针对图查询中典型多跳场景,根据节点的亲和性,对于需要到远端机器执行下一跳的节点集合,可以根据不同机器目的地进行缓存,并按批发送到远端机器。这些节点数据发送到对端机器后,会启动新的子 pipeline 进行并行处理,然后根据 Plan 进行后续处理执行。
分布式存储
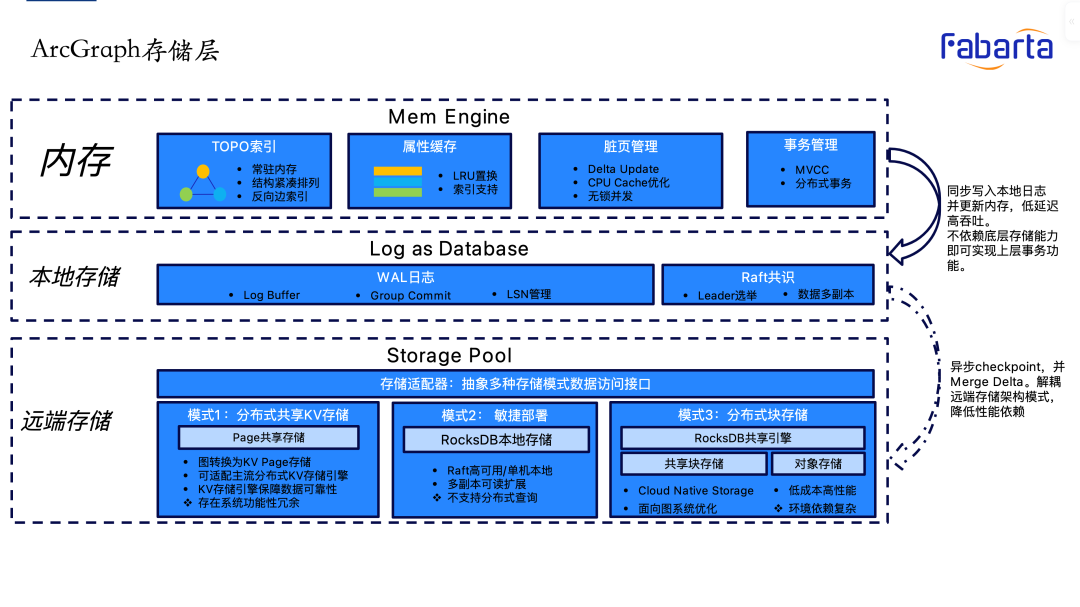
ArcGraph 存储层基于数据温度实现了“热、温、冷”的三级存储结构:
- 首先,提升 ArcGraph 性能的高效内存引擎,包括常驻内存的图拓扑信息,基于 LRU 的点/边属性 Cache,以及支持 DML 功能的 MVCC,脏页管理和 index buffer 管理;
- 下面一层是基于 Log 即 Database 思想的高效本地存储,用来存放 L1 delta,也就是 WAL 日志,并通过 multi-raft 实现节点间的日志同步达到高可用功能。
- 第三层是传统的持久层,为了方便不同场景的灵活部署,系统采用了多种存储方式:快捷部署的单机 RocksDB 部署,大数据量场景的分布式 KV 部署,以及性价比友好的 OSS 存储。
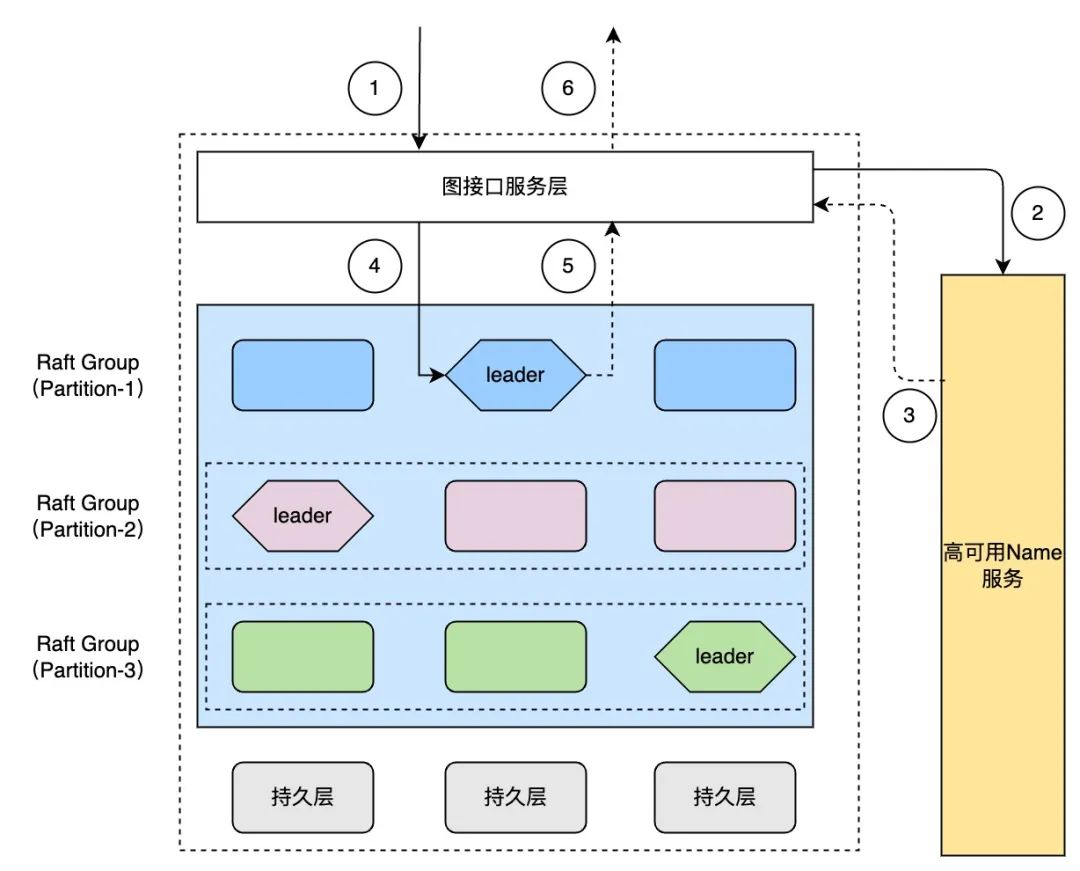
我们以 KV 存储引擎为例,介绍下 ArcGraph 存储功能接口。每个存储节点都有一个 KV 存储引擎作为持久性存储,从上到下提供三个功能:
(1)最上层是计算层提供统一的图查询接口,比如点/边的查询和写入接口。当接到计算层的 Get()或 Put()请求后,首先根据点和边的 Key 在分布式存储中的 NameNode 上查询对应分区拓扑的 Leader 节点信息,然后把请求路由到对应的 KV 节点进行处理。
(2)分布式 KV 存储中间采用 Raft 协议来实现分布式一致性和高可用性。当系统负载发生变化或者存储系统中的节点或者网络出现故障时,分区 Leader 可以人为或基于 Raft 协议自动进行切换。
(3)KV 存储引擎用于实现图点/边数据的持久性;为了节省存储空间,会根据系统配置,对数据进行不同程度的压缩存储。
Semi-Stateful
随着数据库的存算分离,传统数据库的业务 IO 瓶颈已经转化为计算层和存储层之间的 IO 瓶颈,在这种情况下,底层存储节点和网络时延对于响应时间有很大的影响,事务操作的性能也会很大程度上受到影响,尤其是分布式提交等复杂操作。因此,ArcGraph 采用了 Semi-Stateful 架构,继承了“日志即数据”的思想,并在计算层增加本地高性能 SSD 日志 Store,用以对 DML 的 WAL 日志进行存储,并定期对 WAL 日志进行 CheckPoint,并把 Checkponit 数据写入底层存储引擎。这带来了如下优点:
- 在 DML 操作中,只需要记录 WAL 日志,从而显著减少了网络占用。
- 将复杂的 DML 操作由数据和日志的同步操作转变为连续的异步操作。
- 引入了一个分布式的、基于 Raft 协议同步的 WAL 日志服务,降低了网络层或数据存储层问题对数据库的影响。
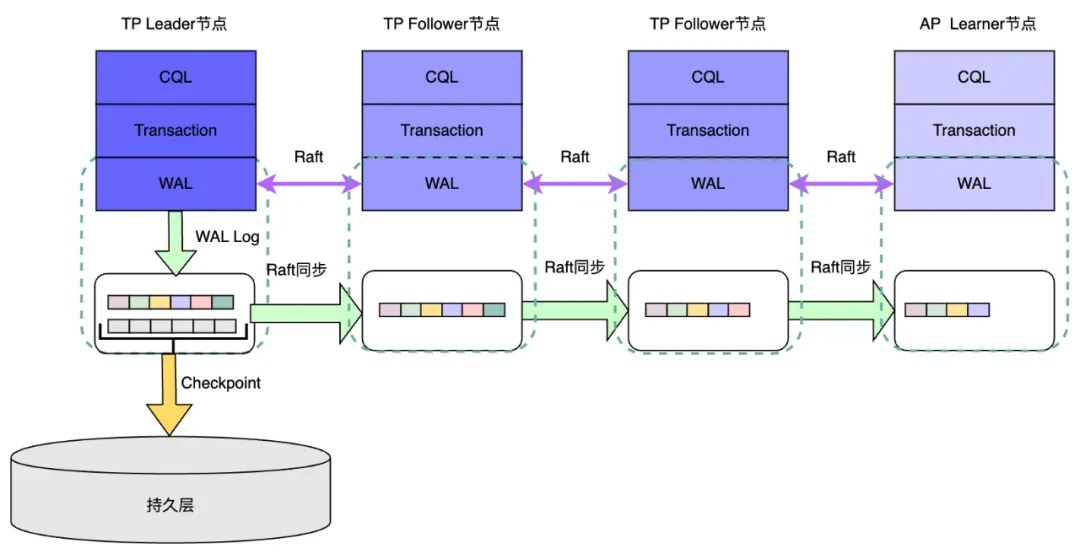
ArcGraph 可采用灵活的分区策略,例如基于点的 ID 或点的 Type 进行 Hash,并采用边的分区跟随起始点的分区策略。通过这种方式,可以将图的点和边数据分为不同的 tablet 分区,每个分区都有多个 WAL 日志的副本,并使用 multi-raft 共识算法来实现 WAL 日志的分布式一致性。在同一个 Raft 组内,节点可以担任不同的角色,包括 Leader、Follower 和 Learner:
- Group Leader :负责接收分区 DML 操作所生成的 WAL 日志写入请求,并在 Raft 组内完成日志的同步及一致性确认, 最后确保成功写入本地的日志 Store;
- 其它 Group Follower 节点(一般是其它 TP 计算节点):完成对 Raft Leader 新的日志进行同步确认,并在心跳超时后发起 Leader 选举;
- Group Learner 节点(通常是 AP 计算节点):对最新的 WAL 日志进行同步,获取最新的 Delta 数据,并将其与从底层存储引擎获取的 Snapshot 数据进行合并,合并后的数据用来完成用户特地场景的 AP 计算(图计算)任务;
图 HTAP
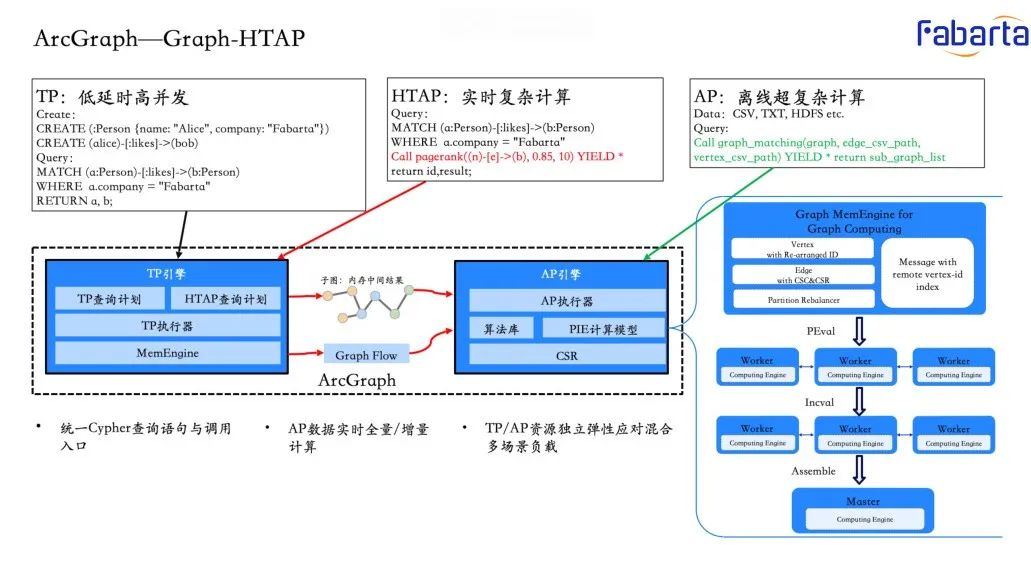
ArcGraph 具备强大的图 HTAP(Hybrid Transactional and Analytical Processing)计算能力,专为低延迟、高并发和复杂的事实计算设计。同时支持 T+1 场景。TP (Transaction Processing)引擎和 AP (Analytical Processing)引擎共享 Cypher Query 前端(Parser,Validator,Planner,Optimizer),根据生成的执行计划,TP 场景的由 TP 引擎分布式并发执行,针对执行计划中的图算法类 AP 算子(比如 SSSP,PageRank),则由 AP 引擎负责进行处理,AP 引擎首先从 TP 引擎获得查询子图,然后进行分布式图计算。此外 AP 引擎也支持从数据库外部加载数据,例如 Hadoop 或者对象存储系统,由此支持了图 HTAP 处理。同时 AP 计算节点实现了 Serverless 能力,可以根据用户请求负载差异,动态扩缩容。
多模态能力
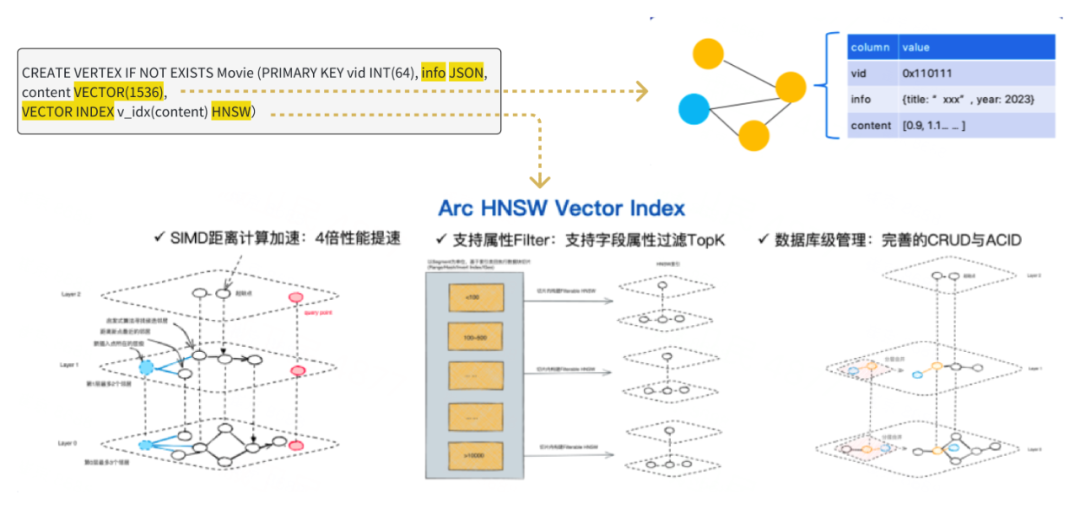
ArcGraph 将向量、JSON和图进行了深度融合。在图的 schema 中,通过为属性字段提供 JSON 类型和向量类型的字段支持,实现了图结构的半结构化和向量能力。 以电影知识图谱为例:影片与制作人作为顶点,形成图拓扑关系,每部电影都有其独特的 ID 和其他信息(如标题、年份等),这些信息我们通过使用 JSON 进行表示。此外,我们将电影的内容或简介文本描述进行向量化处理,并将这些向量数据作为电影顶点的属性字段存储在图数据中。针对向量字段的索引部分,通过 HNSW 索引来加速向量数据的检索。这种索引与图数据的处理结构非常相似,因为它也采用了类似多层图的数据结构。并且使用 HNSW 索引的优点是其检索效率高且召回率较高。为了进一步实现图与向量数据的整合处理,我们在系统中加入了以下三个特性:
- 使用 SIMD 进行距离计算加速,与传统方式相比,我们的方法可以提高 4 倍的性能。
- 支持属性过滤的向量检索功能,同类系统只能进行纯向量检索,而不能进行其他字段(标量)的联合检索。
- 通过原有图技术沉淀,向量数据模型上也实现了完整的 CRUD 和 ACID 功能。
同时 ArcGraph 采用了 “One Query ” 的设计哲学,意在为用户提供一个统一的查询接口。这不仅仅体现在数据模型的统一,更进一步在于查询语言的统一。通过一条查询语句,用户可以同时检索向量数据、JSON 数据和图数据。 延续上面电影知识图谱的例子:当我们创建了一个电影相关的图谱,在这个图谱中找到 2023 年上映的一部反欺诈题材的电影,并进一步查询该电影的导演还拍过哪些其他电影。这个查询任务听起来比较复杂,但在我们的系统中,用户可以使用一条简单的查询语句来完成。具体的查询语句如下所示。其中,黄色的部分是 WHERE 条件,用于筛选 2023 年上映且与反欺诈相关的电影。
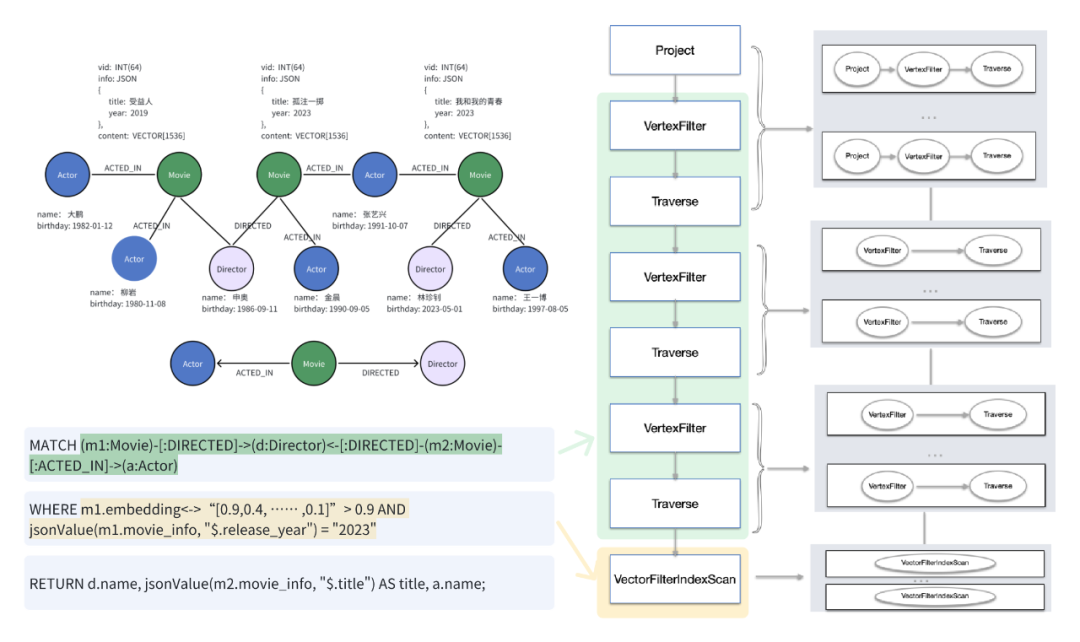
这条查询语句首先会进行一个向量索引扫描,在查询计划里是一个带 FILTER 的向量 INDEX SCAN,筛选出满足条件的电影,然后继续向上传递,使用图算子对结果进行进一步的一跳、两跳查询,例如查询导演和他/她的其他作品。这种设计确保了一条语句可以同时扫描向量数据和图数据,大大简化了用户的业务研发复杂度。
04 总结与展望
总结起来,ArcGraph 是一款云原生架构、存查分析一体化(图 HTAP)的分布式图数据库,采用 Multi-Raft 协议来满足系统的分布式一致性和高可用性;同时支持存储节点和计算节点的无缝扩缩容,支持分布式事务和分布式查询功能;通过采用原图内存引擎,支持高性能图查询和 Serverless 图计算;并且通过图、JSON 和向量的深度融合,实现了 ArcGraph 的多模态能力。接下来,ArcGrapher 将积极拥抱 GQL 图语言标准,进一步优化图内存引擎、执行引擎和存储引擎,提升系统性能和产品易用性。
当下 AI 应用领域正在革命性变革,业内正积极探索构建 AI 可理解的多模态引擎,以实现快速存取和精准推理。在多模态引擎中,图(Graph)将充当多模态引擎的主要结构,结合向量(Vector)引擎来映射多模态数据。ArcGraph 也将通过与公司自研 AI 计算平台和数据智能编织平台的融合,力争实现数据、算力和模型的完美集成,构建出大模型时代的 AI 基础设施,帮助企业快速构建大模型时代的 AI 应用。
如对我们的产品或技术感兴趣,欢迎通过 business@fabarta.com 与我们联系。也可以点击阅读原文,了解更多我们的产品与解决方案信息。
本文作者

戚卫民
Fabarta ArcGraph 架构师
从 0 到 1 构建了 Fabrata ArcGraph 图数据库,长期从事数据库 Kernel 开发及管理工作。曾负责 SAP HANA 西安技术团队管理工作以及相关开发任务,包括 SQL 处理、分布式管理及 HANA 上云等业务。